Under the Hood of Vector Databases: Powering the Next Generation of AI Search

Authored by,
Prashi Rawal (Student, Department of Computer Engineering, Vidyalankar Institute of Technology)
Manali Kulkarni (Student, Department of Computer Engineering, Vidyalankar Institute of Technology)
Shravni Umrani (Student, Department of Computer Engineering, Vidyalankar Institute of Technology)
Asees Kaur (Student, Department of Computer Engineering, Vidyalankar Institute of Technology)
Aditi Shirke(Student, Department of Computer Engineering, Vidyalankar Institute of Technology)
Under the guidance of,
Dr. Amit K. Nerurkar (Faculty, Department of Computer Engineering, Vidyalankar Institute of Technology)
Dr. Prakash Parmar (Faculty, Department of Computer Engineering, Vidyalankar Institute of Technology)
What Is a Vector Database ?
A vector database is a dedicated database system to store, manage, and index high-dimensional vector embeddings to facilitate efficient and quick retrieval and similarity search. An important differentiation has to be made between a vector database and an independent vector index library such as FAISS (Facebook AI Similarity Search). Although a library such as FAISS offers the fundamental algorithms for similarity search, it is not a database system. It does not include basic data management features that exist in production settings. An actual vector database combines these high-capacity indexing features with a complete set of database functionalities, such as:
CRUD Operations: Support for creating, reading, updating, and deleting vector information and its metadata.
Metadata Filtering: The ability to integrate similarity search with standard filtering on metadata.
Scalability and Fault Tolerance: Aspects such as horizontal scaling, sharding, and replication to support large datasets and maintain high availability.
Security: Strong authentication and access control features to safeguard sensitive information.
In essence, a vector database commoditizes the heavy engineering to apply a vector index to a real-world, dynamic application, making the operational complexity easier for developers.
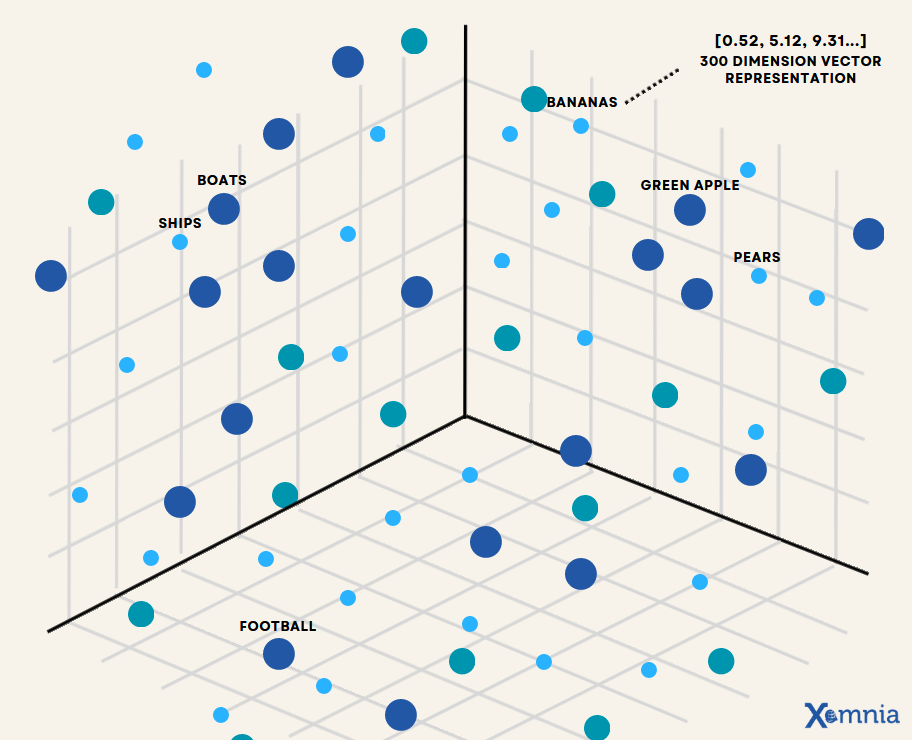
Figure 1: Visualizing Vector Embeddings in a 3D Space
Source: Xomnia (https://www.xomnia.com)
How It Works?
A vector database is a complex system that relies on a step-by-step procedure to make a semantic search possible:
Vectorization (Outside the Database): Data in its raw form, for instance, text, images, or audio, will be converted to vector embeddings with the help of an AI model. To explain the case of text, a model like BERT or GPT is used, whereas for images, CNN based models like ResNet or CLIP are employed. The embeddings represent the semantic part of the data.
Ingestion & Indexing: The app passes the vector and along with that some accompanying metadata (like document ID, tags, or author) to the database. The database saves the information and further updates special indexes, for example, HNSW graphs or IVF clusters to enable quick similarity searches.
Query Processing: A user query (such as a text prompt or an image) will first be converted by the same embedding model into a query vector. The database looks for the closest neighbors in the vector space and hence points to those vectors that are closest in meaning to the query.
Such a procedure gives a semantic match instead of a keyword match. You may compare this to a library: books are indexed by concepts instead of just titles. When you ask a question, the system delivers the most relevant 'chapters' rather than making you guess the right keyword.
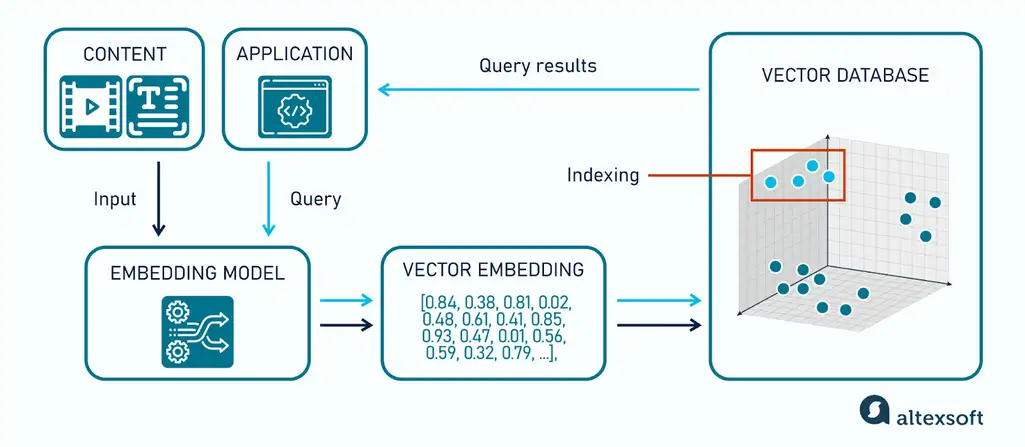
Figure 2: Workflow of a Vector Database
Source: AltexSoft (https://www.altexsoft.com)
Why Traditional Search Falls Short ?
For many years, search was largely based on keywords. If you enter the word "smartphone" in a search box, the results that you will get will mostly be those that have the word "smartphone" written in them. This method of lexical search works fine if you know exactly the term that you need, but it is not very good in real life because of several limitations:
Lack of semantic understanding: The result of a search for "cellphone" will not include "mobile device" even if they're semantically identical.
Contextual limitations: A search for "apple recipes" might also return results like recipes for pairing apples with certain cheeses. This means the next step after searching would involve reading about "apples" in this context.
Dependence on exact matches: Instead of describing their informational needs, users have to come up with keywords that are in the document.
The difference between what people really want and what search engines offer is called the semantic gap. It makes keyword-based searches very annoying and less efficient in today's world where the majority of data is unstructured, and this includes text, images, audio, and video. Vector databases solve this problem by changing the focus from word matching to comprehension of meaning, intent, and context.
Applications
Vector databases are indeed pivotal in modern artificial intelligence systems, enabling them to understand and process data comprehensively. These systems can grasp entire concepts, unlike traditional search or databases that provide results limited to specific queries. Some of the most influential use cases of vector databases include:
Retrieval-Augmented Generation (RAG): In every use of a Large Language Model (LLM) like ChatGPT, there are many scientific wonders and implications. However, these models don't always understand your specific documents or the most recent data. Vector databases allow them to access external storage that acts like a memory bank. A vector is created from the user's query, which is then compared with vectors from the stored information. The most relevant information is then added to the model's output, making the findings more reliable and verifiable.
Semantic Search: Keyword searches have limitations. For example, if you search for "mobile device," you might miss texts that only use the word "cellphone." Vector databases first identify and connect queries with results that are semantically similar, even if they don't use the exact same words.
Multimodal Search: One major advantage of vectors is that they can represent different types of data such as text, images, audio, or video within the same database.
Fraud and Anomaly Detection: Vector embeddings can show what is considered 'normal' in terms of transactions and activities. If a new transaction or behavior is very different from this norm, it can be flagged as unusual. Banks use this technique to detect fraudulent credit card transactions, and cybersecurity systems use it to spot abnormal network traffic.
Autonomous Systems: Autonomous vehicles and robots generate large amounts of sensor data. Vector databases help identify objects, patterns, or environments by comparing new data with stored data from similar situations, providing instant information. For example, an autonomous vehicle must quickly decide if an object in front of it is a pedestrian, a traffic cone, or another vehicle, often within seconds.
Challenges & Trade-offs
Even though vector databases have impressive features, they still face some challenges. There are certain limitations when building and deploying them in real-world scenarios.
The Curse of Dimensionality: With high-dimensional vectors, the difference between the nearest and farthest points becomes so small that it's hard to tell them apart. Without advanced indexing techniques, searching becomes very complicated. Often, speed and accuracy are traded off in vector searches.
Speed vs. Accuracy: Approximate Nearest Neighbor (ANN) algorithms are used to improve speed, offering results that are "close enough." This trade-off is acceptable in applications like e-commerce but not in fields like healthcare, where precision is crucial.
Memory and Storage Needs: Indexes like HNSW graphs or IVF clusters require a lot of memory to support efficient searches. Storage for large data files can become very extensive. One way to address this issue is by using compression methods like Product Quantization, which can partially solve the problem but slightly reduce accuracy.
Scalability and System Complexity: Strategies for handling large data, such as replication and sharding, make the system scalable and fault-tolerant. However, these benefits come with the downside of increased engineering complexity and costs.
Next Generation AI Search
The AI search of the future will hardly be recognizable from the present one. We will have the ability to reach the searched data in a much more rapid and simple way. Some of the primary factors in AI next-generation search are:
Hybrid Search: The approach depends on the close integration of the best features from both worlds. It takes the concepts that are derived from the keywords of a query result and applies them to the semantic understanding to match the found data more closely with the query.
Multimodal Search: The trend is about the elimination of the barriers between different data types. It makes it possible for different data types to be accessed as if they were just different views of the same object thus facilitating searching and browsing.
AI-Integrated Databases: The concept of AI-integrated databases is not only about handling regular data. They also manage embeddings, model versions, and analytics, which, in turn, give the ability to handle complex AI-powered inquiries.
Hardware Acceleration: The detailed search that is usually supported by GPU and other accelerators is now available in real-time searches magnitudes of a billion with the help of GPUs and other such devices thus very much increasing the search turnover rate.
Future systems will allow searches across multiple databases without exposing raw data—preserving privacy while still delivering meaningful results.
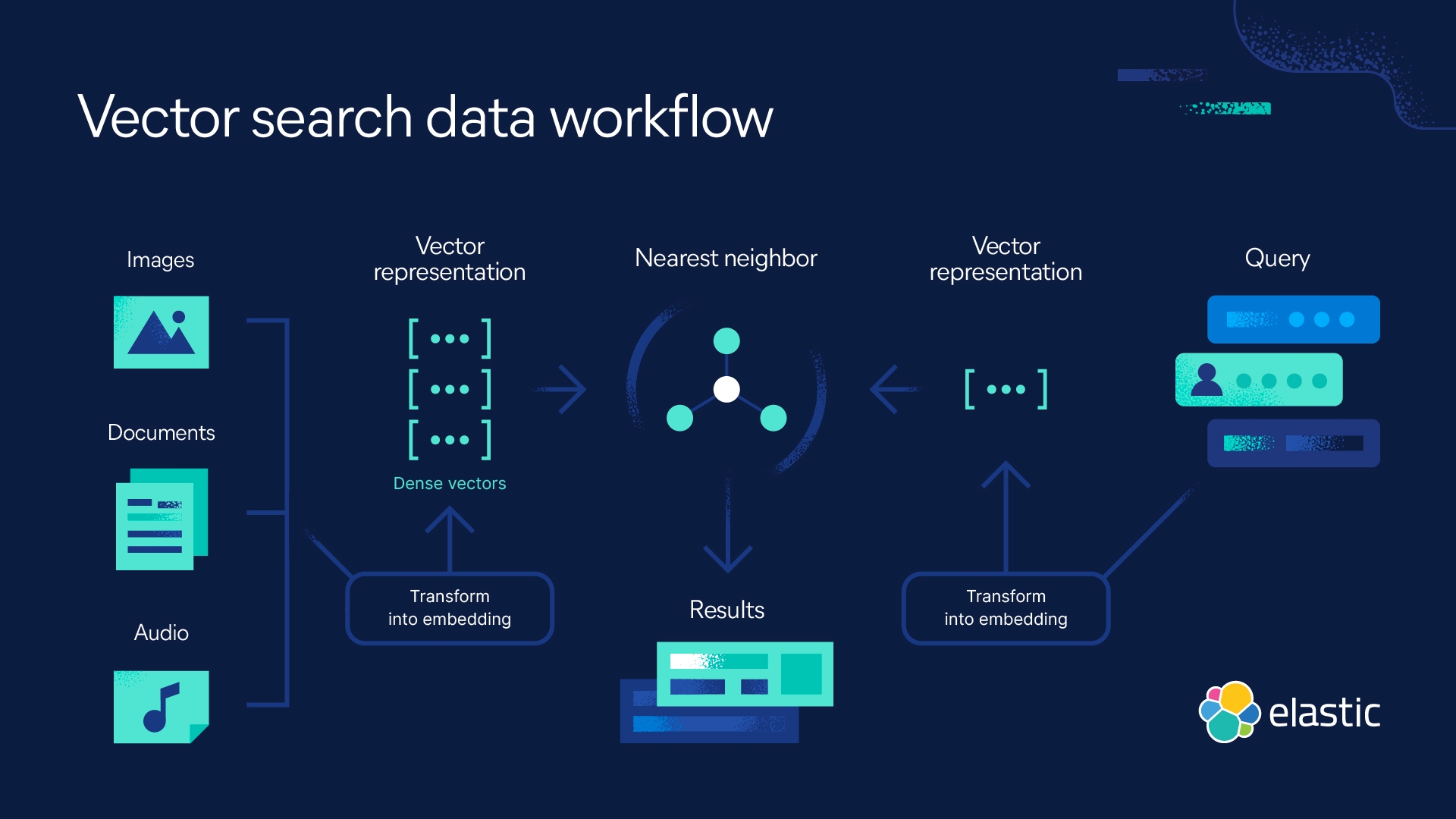
Figure 3: Vector Search Workflow for Next-Generation AI
Source: elastic (https://www.elastic.co/what-is/vector-search)
Simply put, the development of AI search is rapidly moving forward to the point where natural language systems comprehend the same queries as humans but in a less complex manner for users not to have to change their thinking to that of the machine.
Conclusion
Vector databases play a crucial role in transforming AI into a more efficient tool for exploring and understanding data. While they can't fully replace traditional keyword-based searches, they focus on the semantic meaning and context of data, which is vital for building smart systems. This feature allows users to employ them in more advanced ways, such as using chatbots, personalized recommendations, advancements in the medical field, and creating autonomous systems.
Despite challenges like balancing speed with precision and memory with scalability, vector databases still offer a vast number of vectors to be utilized. These enable searches that mimic human behavior, making interactions with the system intuitive and user-friendly. AI development will continue, and the use of vectors will become as essential as GPUs in the future of deep learning. This means they will be key players in the next stages of AI, shaping a future where data retrieval is not only simpler but also more comfortable and aligned with human needs.
References
What is a Vector Database & How Does it Work? Use Cases + ..., accessed October 1, 2025, https://www.pinecone.io/learn/vector-database/
What Is A Vector Database? - IBM, accessed October 1, 2025, https://www.ibm.com/think/topics/vector-database
What is a Vector Database? - AWS, accessed October 1, 2025, https://aws.amazon.com/what-is/vector-databases/
What is vector search? Better search with ML - Elastic, accessed October 1, 2025, https://www.elastic.co/what-is/vector-search
A quick introduction to vector search - Elasticsearch Labs, accessed October 1, 2025, https://www.elastic.co/search-labs/blog/introduction-to-vector-search
Enhancing AI retrieval with HNSW in RAG applications - IBM Developer, accessed October 1, 2025, https://developer.ibm.com/tutorials/awb-enhancing-retrieval-hnsw-rag/
Vector Database: 13 Use Cases—from Traditional to Next-Gen - NetApp Instaclustr, accessed October 1, 2025, https://www.instaclustr.com/education/vector-database/vector-database-13-use-cases-from-traditional-to-next-gen/
What are the trade-offs between speed and accuracy in vector search? - Zilliz, accessed October 1, 2025, https://zilliz.com/ai-faq/what-are-the-tradeoffs-between-speed-and-accuracy-in-vector-search
Image Credits
Cover image: © Getty Images, via Intersystems (https://www.intersystems.com)
Figure 1: Visualizing Vector Embeddings in a 3D Space - Xomnia
Figure 2: Workflow of a Vector Database - AltexSoft
Figure 3: Vector Search Workflow for Next-Generation AI – Elastic